Deezer Music Recommender - Hybrid ML System
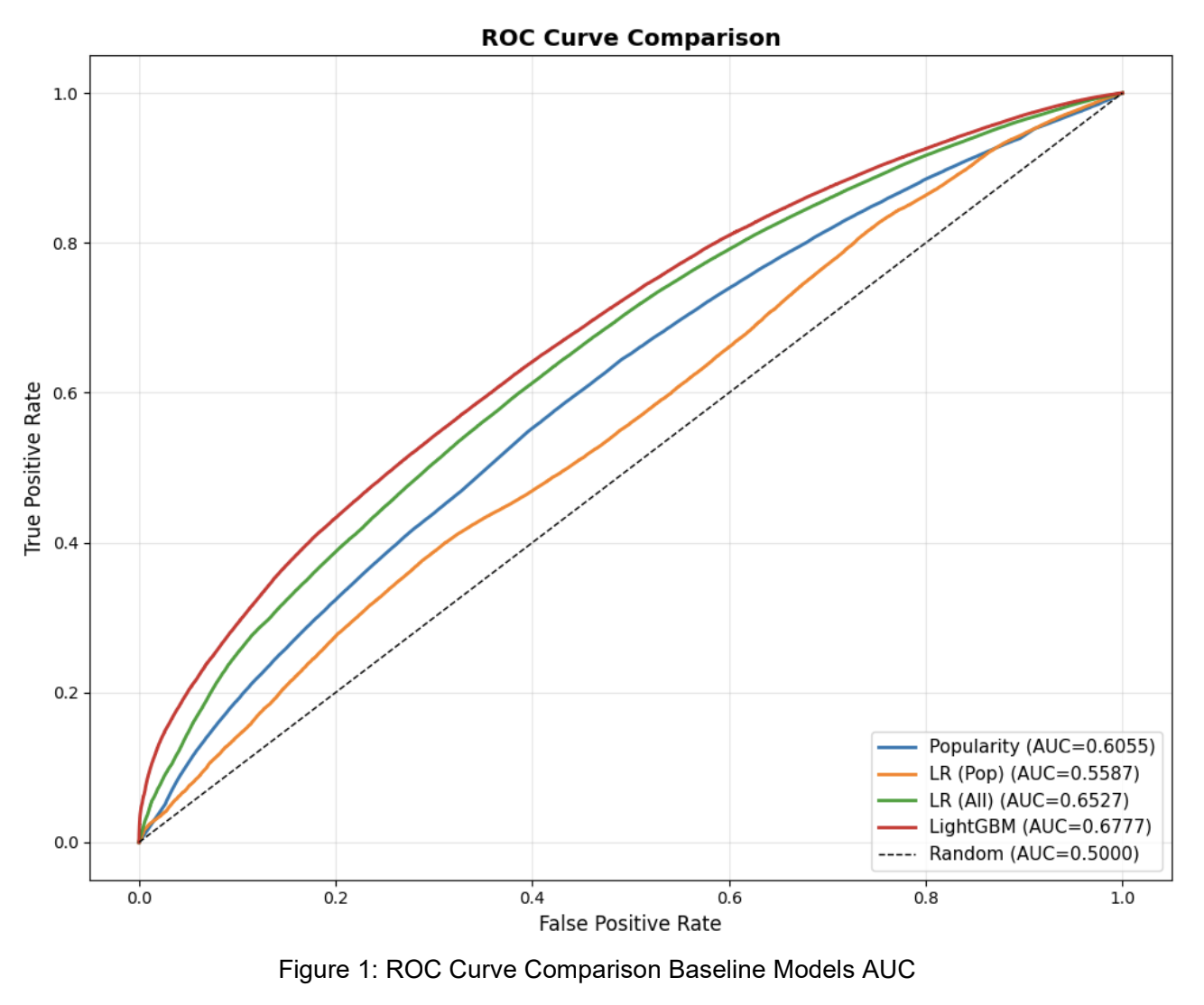
Baseline ROC curves: LightGBM (AUC 0.6777) outperforms linear models, confirming that non-linear feature interactions drive predictive power
Team project with Julia Stadelmann and Semrawit Haile (Recommender Systems course, HSLU). Jan 2025.
Overview
Deezer operates a catalog of 43 million tracks across 180+ countries and must predict in real time whether a user will engage with a recommended song — defined as listening for more than 30 seconds without skipping. We addressed this as a binary classification problem on 7.56M listening events from 19,918 users and 452,955 songs: a >99% sparse interaction matrix with class imbalance (68.4% positive) and temporal drift (98% of events concentrated in Nov–Dec 2016).
Modeling Pipeline
The system combines three signal types in sequence, each addressing a different aspect of the prediction problem:
- User Affinity Features — Five personalized features capturing user-song compatibility from training history: genre affinity, artist affinity, age compatibility, platform match, and time match. Each is a ratio computed per (user, song) pair, with global statistics as fallback for cold-start users.
- Matrix Factorization Embeddings — Pointwise MF with 64-dimensional user and song embeddings (PyTorch, BCE loss), trained on the chronological split. Produces a compatibility score and embedding vectors for each known user-item pair.
- Hybrid LightGBM — Combines original contextual features (21 engineered), affinity signals from stage 1, and CF outputs (embedding scores + representations) from stage 2 into a single gradient boosting model. A binary indicator flags cold-start cases where collaborative signals are unavailable.
The key design principle: each stage generates features that feed into the final model, not standalone predictions. The LightGBM model learns the optimal weighting between content-based and collaborative signals automatically.
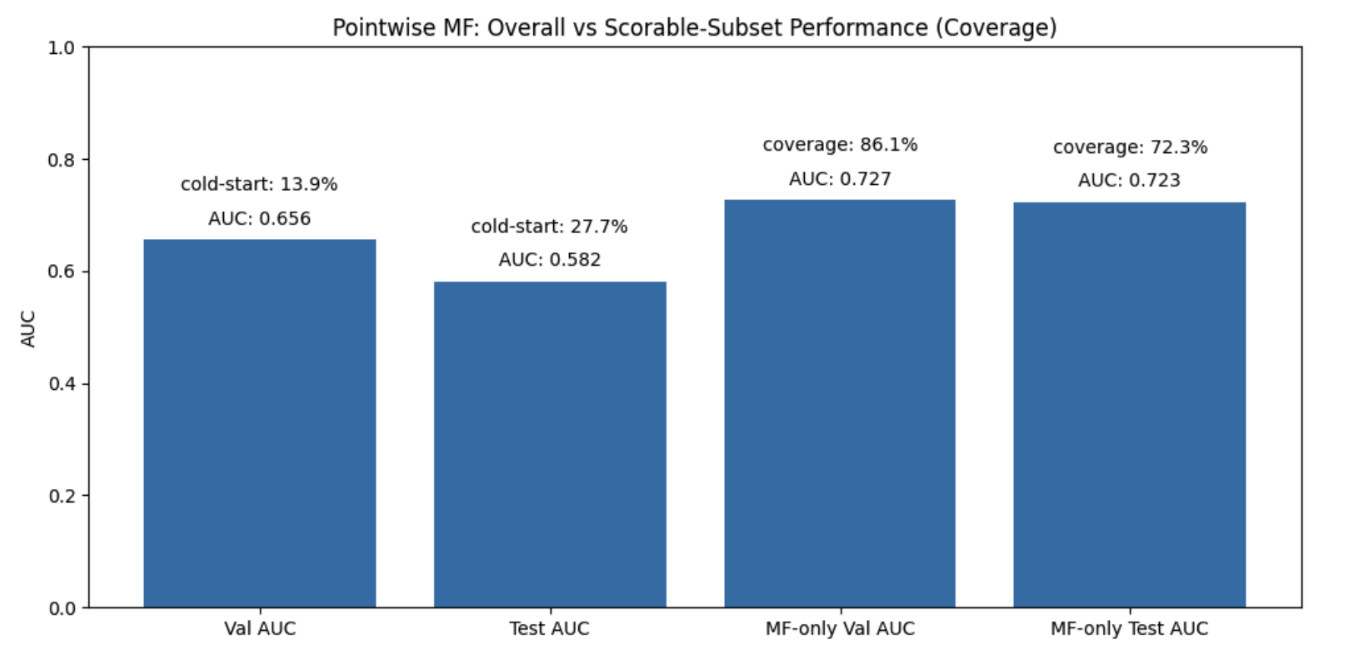
Cold-start impact on matrix factorization: AUC drops from 0.723 (scorable pairs) to 0.582 (all pairs) as 27.7% of test interactions involve unseen users or songs
Technical Decisions
LightGBM over logistic regression or neural rankers: The EDA revealed that individual features have weak linear correlation with the target (platform_name: +0.171, listen_type: -0.120), but non-linear interactions are strong — LightGBM baseline immediately outperformed all linear models (0.6777 vs 0.6527 AUC). A neural two-tower model was considered but rejected given the dataset size and the fact that the embedding signal was already captured by the MF stage.
Ratio-based affinity features over learned embeddings: The affinity features (e.g., genre_affinity = user’s listens in song’s genre / total listens) are interpretable, computable for any user with history, and require no additional training infrastructure. They performed poorly in isolation under linear models but ranked among the top-5 most important features in the final LightGBM hybrid — a finding that shaped how I think about feature validation (see What I Learned).
Strict chronological split over k-fold: With 98% of events in two months, random k-fold would train on future data. We used a global temporal cutoff (80/10/10 by timestamp), which revealed genuine temporal drift — positive rate declined from 69.1% (train) to 64.1% (test). Early experiments with inconsistent time splits produced AUC of 0.9, clearly unrealistic.
Results
| Model | Test AUC |
|---|---|
| Popularity Baseline | 0.6055 |
| LightGBM Baseline | 0.6777 |
| Pointwise MF (scorable pairs only) | 0.7232 |
| Hybrid Model (default params) | 0.6844 |
| Hybrid + Hyperparameter Tuning | 0.7477 |
The untuned hybrid (0.6844) slightly underperforms MF on scorable pairs because the default LightGBM hyperparameters don’t adequately balance the diverse feature types — collaborative embeddings, affinity ratios, and raw contextual features operate at different scales and interaction depths. After tuning (learning rate, tree depth, regularization via chronological cross-validation), the hybrid reaches 0.7477, outperforming every individual model including MF’s scorable-only subset, while maintaining full coverage on cold-start cases.
My Contribution
I authored 5 of the 8 project notebooks:
- 01 — EDA: Dataset profiling, feature correlation analysis, class imbalance and temporal concentration findings
- 02 — Preprocessing & Feature Engineering (with Semrawit Haile): Temporal train/validation/test split, 21 derived features, data quality corrections (650 outlier rows removed)
- 03 — Baseline Models: Popularity, Logistic Regression, and LightGBM baselines with ROC curve comparison
- 04 — Test Set Analysis: Cold-start rate quantification, positive rate drift analysis across splits
- 05 — User Affinity Features: Five personalized features with cold-start fallback, overfitting analysis, and interpretation of linear vs. tree-based model behavior
Julia Stadelmann contributed the Collaborative Filtering implementation (06) and the Hybrid Model with hyperparameter tuning (07, 08).
What I Learned
The most surprising finding was that well-designed features can fail catastrophically in one model and excel in another. The affinity features I built showed severe overfitting under logistic regression (train AUC 0.667 → test AUC 0.487) — LR assigned near-zero weight to all five features and effectively suppressed them. My initial reaction was that the features were broken. But in the LightGBM hybrid, those same features ranked among the top-5 most important. The difference is that ratio-based features are inherently relational: a genre_affinity of 0.4 means different things depending on the user’s total activity, the song’s context, and the listening platform. Linear models treat each feature independently and learn spurious correlations; tree-based models can condition on these interactions. This experience changed how I think about feature validation — a feature’s value depends on the model’s capacity to use it.
Technology Stack
- ML: LightGBM, PyTorch (matrix factorization with BCE loss), scikit-learn
- Data: pandas, NumPy, SciPy (sparse matrices for 18,153 x 403,288 training interaction matrix)
- Evaluation: ROC-AUC, HitRate@10, NDCG@10, cold-start coverage tracking
Code available on request.